02: Logistic Regression#
import itertools
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import make_axes_locatable
from sklearn.linear_model import LinearRegression
from sklearn.metrics import log_loss, mean_squared_error
import torch
from torch import nn
In the first part we created a neural network for linear regression (i.e. for a continuous output value \(y\)). In this part we’ll move on to binary classification (i.e. where \(y\) can belong to one of two classes \(y \in \{0, 1\}\)), starting with logistic regression.
Why not just use linear regression for classification?#
Linear regression returns a continuous value (\(-\infty \leq y \leq \infty\)), but we want a class probability (\(0 \leq y \leq 1\))
Very sensitive to outliers/imbalanced data
Here’s an example of using linear regression on a classification dataset with a single feature, \(x\):
def fit_and_plot(x, y, title="", ax=None):
if ax is None:
_, ax = plt.subplots(1, 1)
lr = LinearRegression()
lr.fit(x.reshape(-1, 1), y)
yhat = lr.predict(x.reshape(-1, 1))
ax.scatter(x, y, c=yhat >= 0.5, cmap="bwr")
ax.plot(x, yhat, "k--", label="linear fit")
ax.set_ylim([-0.2, 1.2])
ax.legend(loc="lower right")
ax.set_ylabel("y")
ax.set_xlabel("x")
ax.set_title(title)
xy = np.loadtxt("../data/02_dummy_data.csv")
x = xy[:, 0]
y = xy[:, 1]
fig, ax = plt.subplots(1, 2, figsize=(9, 4))
fit_and_plot(x, y, title="balanced", ax=ax[0])
fit_and_plot(np.append(x, [4, 5]), np.append(y, [1, 1]), title="+ outliers", ax=ax[1])
fig.tight_layout()
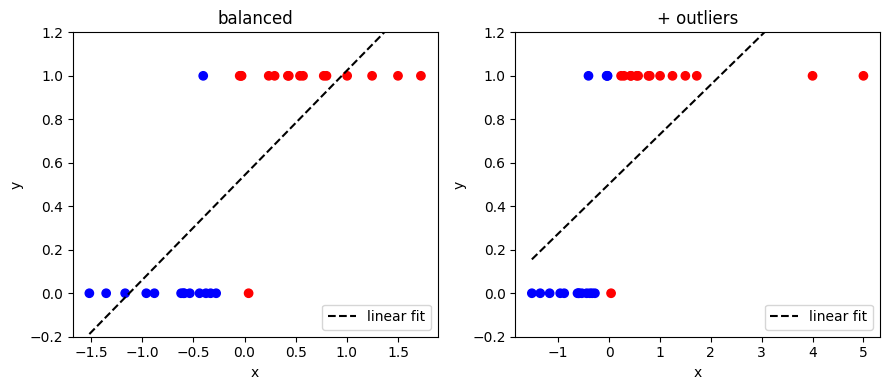
Note that:
The range of \(y\) is not limited to between 0 and 1
The presence of the outliers changes the predicted class of a point (and e.g. changes the value of \(y\) from around -0.2 to +0.2 for \(x = -1.5\))
The solution: Sigmoid#
To get around this we apply the sigmoid function:
which is bounded between zero and one, and looks like this:
def sigmoid(z):
return 1 / (1 + np.exp(-z))
z = np.linspace(-10, 10, 100)
plt.figure(figsize=(4,3))
plt.plot(z, sigmoid(z))
plt.xlabel("z")
plt.ylabel("sigmoid(z)")
Text(0, 0.5, 'sigmoid(z)')
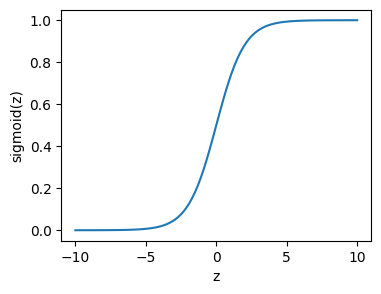
The logistic regression model is:
Note we still use a linear predictor, \(z\):
on the input features, which we apply the sigmoid function to create our final output (mapping the continuous value of the linear predictor to be between zero and one):
Loss Function#
In linear regression we used mean squared error as the metric to optimise the weights of the model. In logistic regression we use the log loss, also known as the (binary) cross-entropy loss. It’s defined as follows (remember that \(y\), the true class, is always zero or one):
Which looks like this:
yhat = np.linspace(0.01, 0.99, 99)
plt.figure(figsize=(5, 4))
plt.plot(yhat, -np.log(yhat), label="y = 1")
plt.plot(yhat, -np.log(1 - yhat), label="y = 0")
plt.legend(loc="upper center")
plt.xlabel(r"$\hat{y}$ (prediction)")
plt.ylabel("loss")
Text(0, 0.5, 'loss')
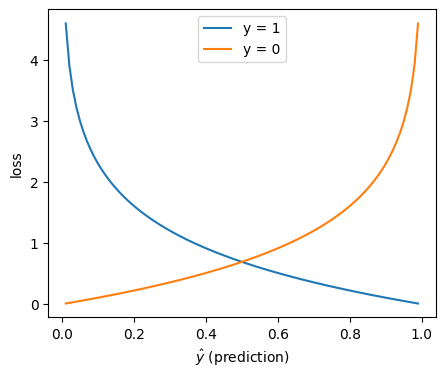
Why not just use mean squared error?#
1) It’s the Maximum Likelihood Estimator#
In logistic regression we model the true class label (\(y_i=1\) or \(y_i=0\)) as being drawn from a Bernoulli distribution, where the probability of \(y_i = 1\) is given by our prediction \(\hat{y_i}\):
We want to maximise the likelihood (the probability of the true class values given our predictions):
Often it’s more convenient to work with the log likelihood instead:
Note the change from a product to a sum follows from log rules (\(\log (ab) = \log(a) + \log(b)\)).
This can be re-written as:
In logistic regression with gradient descent, rather than maximising the log likelihood we minimise its negative and take the mean across the dataset:
This is exactly the binary cross-entropy loss introduced before.
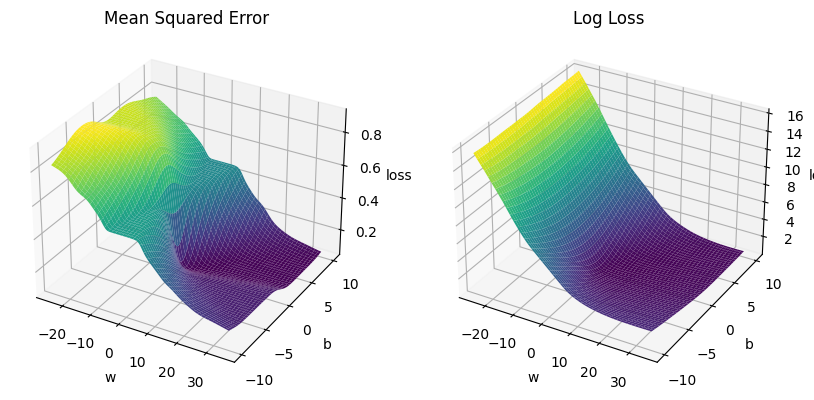
2) It’s convex#
It’s a convex function for logistic regression (but mean squared error is not), see below. So it’s easier to optimise, as there are no local minima.
ws = np.linspace(-25, 35, 200)
bs = np.linspace(-10, 10, 200)
mse_ls = []
bce_ls = []
w_plot = []
b_plot = []
for w, b in itertools.product(ws, bs):
w_plot.append(w)
b_plot.append(b)
yhat = sigmoid(w * x + b)
mse_ls.append(mean_squared_error(y, yhat))
bce_ls.append(log_loss(y, yhat))
fig, ax = plt.subplots(1, 2, subplot_kw={"projection": "3d"}, figsize=(10, 8))
surf = ax[0].plot_surface(
np.array(w_plot).reshape((len(ws), len(bs))),
np.array(b_plot).reshape((len(ws), len(bs))),
np.array(mse_ls).reshape((len(ws), len(bs))),
cmap="viridis"
)
ax[0].set_title("Mean Squared Error")
ax[0].set_xlabel("w")
ax[0].set_ylabel("b")
ax[0].set_zlabel("loss")
# Plot the surface.
surf = ax[1].plot_surface(
np.array(w_plot).reshape((len(ws), len(bs))),
np.array(b_plot).reshape((len(ws), len(bs))),
np.array(bce_ls).reshape((len(ws), len(bs))),
cmap="viridis"
)
ax[1].set_title("Log Loss")
ax[1].set_xlabel("w")
ax[1].set_ylabel("b")
ax[1].set_zlabel("loss")
Text(0.5, 0, 'loss')
Gradient Descent for Logistic Regression#
In gradient descent we iteratively update the parameters based on the gradient of the loss with respect to them, with a step size given by a learning rate \(\alpha\):
The aim is to reach the minimum value of the loss, where the gradients are zero.
For logistic regression the gradients are given by:
To derive these you need to know the derivative of the sigmoid function and the chain rule from calculus, which we’ll see in the next notebook.
Neural Network for Logistic Regression#
To modify our simple linear regression neural network for logistic regression we need to add an activation function:
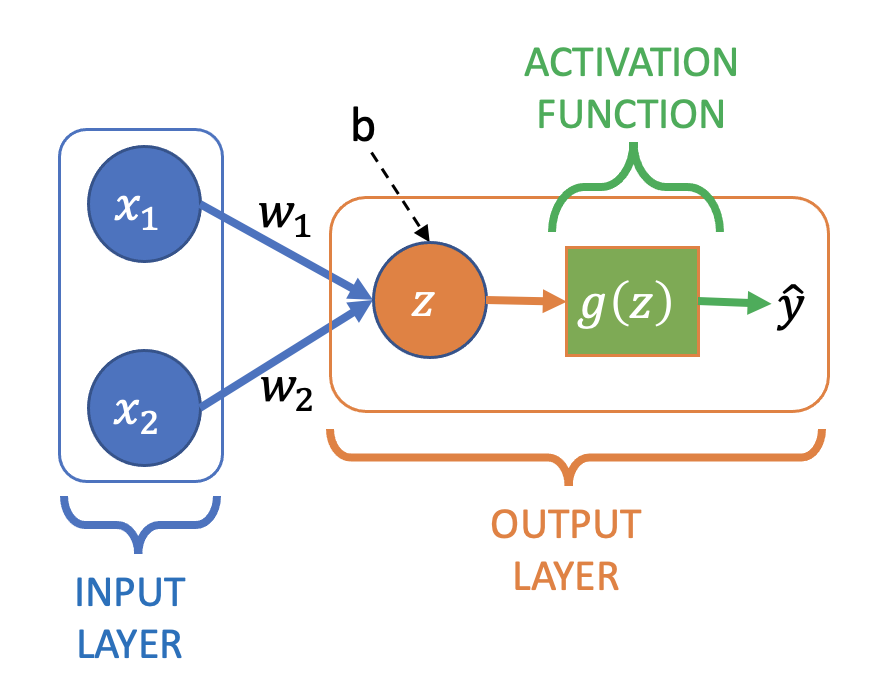
Where \(z\) is still the a linear combination of the output node’s inputs:
which then has the sigmoid activation function, \(g(z)\), applied to it to create the final output:
Often you’ll see \(g(z)\) (i.e. the computation of \(z\) and the application of \(g\)) drawn as a single node in diagrams, rather than explicitly separating them.
Pytorch#
Here is a logistic regression “neural network” implemented in pytorch, which we’ll use with the BCELoss (Binary Cross Entropy, aka the log loss defined earlier). Initially just for the dummy dataset we’ve used so far with a single input feature:
model = nn.Sequential(
nn.Linear(in_features=1, out_features=1),
nn.Sigmoid()
)
print(model)
loss_fn = nn.BCELoss()
Sequential(
(0): Linear(in_features=1, out_features=1, bias=True)
(1): Sigmoid()
)
For improved numerical stability (see the pytorch docs and this article for details) it’s preferred to combine the sigmoid and loss functions into one step. This is done by using BCEWithLogitsLoss:
model = nn.Sequential(
nn.Linear(in_features=1, out_features=1),
)
print(model)
loss_fn = nn.BCEWithLogitsLoss()
Sequential(
(0): Linear(in_features=1, out_features=1, bias=True)
)
Note that sigmoid no longer appears in the network definition, and if the model is trained this way its output will be \(z\), not \(g(z)\) (i.e. we need to apply the sigmoid function to the output to recover the class probabilities).
Everything else about training the network is the same we saw in the first part for linear regression:
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
def train(X, y, model, loss_fn, optimizer, epochs):
loss_history = []
for e in range(epochs):
# Compute prediction and loss
pred = model(X)
loss_value = loss_fn(pred, y)
loss_history.append(float(loss_value))
# Backpropagation
optimizer.zero_grad()
loss_value.backward()
optimizer.step()
print("Done!")
return model, loss_history
x = torch.tensor(x, dtype=torch.float)
y = torch.tensor(y, dtype=torch.float)
x = x[:, None]
y = y[:, None] # input and output needs to be 2D, [:, None] adds a second (length 1) axis
model, loss_history = train(x, y, model, loss_fn, optimizer, 15000)
for name, param in model.named_parameters():
print(f"Layer: {name} | Size: {param.size()} | Values : {param[:]} \n")
Done!
Layer: 0.weight | Size: torch.Size([1, 1]) | Values : tensor([[5.4283]], grad_fn=<SliceBackward0>)
Layer: 0.bias | Size: torch.Size([1]) | Values : tensor([0.8135], grad_fn=<SliceBackward0>)
Here’s the fit to the data:
fig, ax = plt.subplots(1, 2, figsize=(9, 3))
ax[0].plot(loss_history)
ax[0].set_xlabel("epochs")
ax[0].set_ylabel("loss")
yhat = sigmoid(model(x).detach().numpy()) # need to apply sigmoid here due to use of BCEWithLogitsLoss
ax[1].scatter(x, y, c=yhat>=0.5, cmap="bwr")
ax[1].plot(x, yhat, "k--", label="sigmoid fit")
ax[1].set_xlabel("x")
ax[1].set_ylabel("y")
boundary = - model[0].bias[0].detach() / model[0].weight[0][0].detach()
ax[1].plot([boundary, boundary], [-0.1, 1.1], "g", linewidth=3, label="decision boundary")
ax[1].set_ylim([-0.05, 1.05])
ax[1].legend(loc="lower right")
fig.tight_layout()
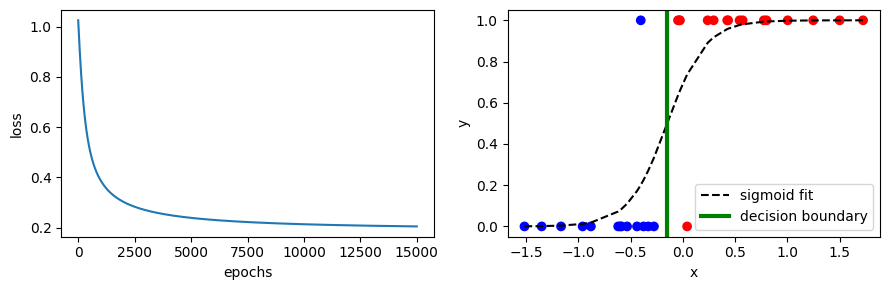
Also shown is the decision boundary - all samples with \(x\) to the left of the boundary are predicted to have \(y = 0\), and all values to the right \(y = 1\) (assuming we predict \(y = 1\) when \(\hat{y} \geq 0.5\)).
Adding a second feature#
Now let’s consider a more interesting dataset with two features, \(x_1\), \(x_2\), and a non-linear decision boundary. In this case samples belong to class 1 if \(x_1^3 - x_1 - x_2 > 0\) (and class 0 otherwise):
def get_cubic_data(n=1000):
X = np.random.normal(size=(n, 2))
y = X[:, 1] < (X[:, 0] ** 3) - X[:, 0]
return X, y
X, y = get_cubic_data()
fig, ax = plt.subplots(1, 2, figsize=(9.5, 4))
ax[0].scatter(X[:, 0], X[:, 1], c=y, cmap="bwr", s=18)
ax[0].set_xlabel("$x_1$")
ax[0].set_ylabel("$x_2$")
x_span = np.linspace(X[:, 0].min() - 1, X[:, 0].max() + 1, 1000)
ax[0].plot(x_span, x_span ** 3 - x_span, "k--", label="$x_1^3 - x_1 - x_2 = 0$")
ax[0].set_ylim([-4, 4])
ax[0].legend()
z = X[:, 0] ** 3 - X[:, 0] - X[:, 1]
ax[1].scatter(z, y, c=y, cmap="bwr")
ax[1].plot([0, 0], [-0.1, 1.1], "k--", label="$x_1^3 - x_1 - x_2 = 0$")
ax[1].legend()
ax[1].set_xlabel("$x_1^3 - x_1 - x_2$")
ax[1].set_ylabel("y")
fig.tight_layout()
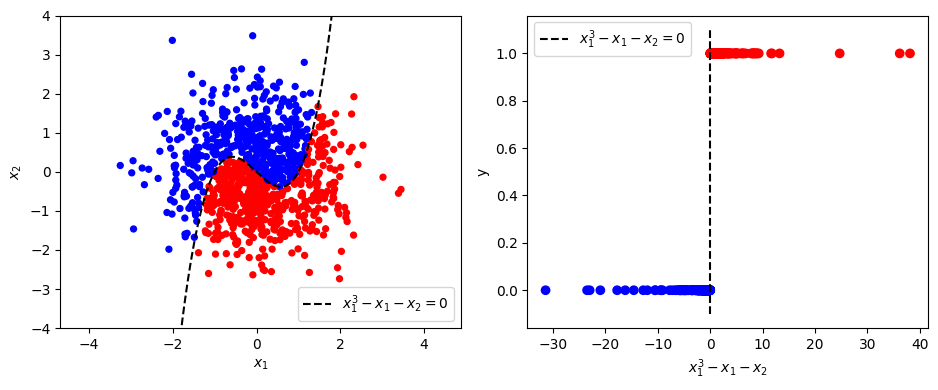
Pytorch 2-input Logistic Regression Network#
model = nn.Sequential(
nn.Linear(in_features=2, out_features=1), # 2 input features now (x_1, x_2)
# Sigmoid (applied in loss_fn)
)
loss_fn = nn.BCEWithLogitsLoss()
# Reminder: BCEWithLogitsLoss both applies sigmoid to the output and computes the loss
What type of decision boundary can this network fit (given \(x_1\) and \(x_2\))?#
a) Linear
b) Non-linear
Reminder: We’ve added a non-linear activation function (sigmoid)
Result#
X = torch.tensor(X, dtype=torch.float)
y = torch.tensor(y, dtype=torch.float)
y = y[:, None]
def plot_decision_boundary(
dataset,
labels,
model,
steps=1000,
cmap="bwr",
ax=None,
show_data=True,
show_actual=True,
title="Decision Boundary Fit",
xlim=None,
ylim=None,
xlabel="$x_1$",
ylabel="$x_2$",
alpha=0.25,
fig=None,
vmin=0,
vmax=1,
):
"""
Adapted from:
https://gist.github.com/erwan-simon/e3baef06a00bb9a39a6968acf78121ee
"""
# Define region of interest by data limits
if xlim:
xmin, xmax = xlim
else:
xmin, xmax = dataset[:, 0].min() - 1, dataset[:, 0].max() + 1
if ylim:
ymin, ymax = ylim
else:
ymin, ymax = dataset[:, 1].min() - 1, dataset[:, 1].max() + 1
if ax is None:
fig, ax = plt.subplots()
if fig is None:
fig = ax.get_figure()
x_span = np.linspace(xmin, xmax, steps)
y_span = np.linspace(ymin, ymax, steps)
xx, yy = np.meshgrid(x_span, y_span)
# Make predictions
labels_predicted = model(
torch.tensor(np.c_[xx.ravel(), yy.ravel()], dtype=torch.float)
)
labels_predicted = sigmoid(labels_predicted.detach().numpy())
# Plot predictions
z = np.array(labels_predicted).reshape(xx.shape)
cf = ax.contourf(xx, yy, z, cmap=cmap, alpha=alpha, vmin=vmin, vmax=vmax)
divider = make_axes_locatable(ax)
cax = divider.new_horizontal(size="5%", pad=0.2)
fig.add_axes(cax)
fig.colorbar(cf, cax=cax)
# plot data
if show_data:
ax.scatter(
dataset[:, 0],
dataset[:, 1],
c=labels.reshape(labels.size()[0]),
cmap=cmap,
lw=0,
marker="."
)
ax.set_xlabel(xlabel)
ax.set_ylabel(ylabel)
ax.set_title(title)
if not show_data and show_actual:
ax.plot(x_span, x_span ** 3 - x_span, "k--", label="actual")
ax.set_ylim([ymin, ymax])
ax.legend()
def show_result(X, y, model, loss_history, print_weights=True, suptitle=""):
if print_weights:
for name, param in model.named_parameters():
print(f"Layer: {name} | Size: {param.size()} | Values : {param[:]} \n")
fig, ax = plt.subplots(1, 3, figsize=(10, 3))
ax[0].plot(loss_history)
ax[0].set_xlabel("epoch")
ax[0].set_ylabel("loss")
plot_decision_boundary(X, y, model, ax=ax[1], show_data=False)
plot_decision_boundary(X, y, model, ax=ax[2], show_data=True, title="Data")
fig.suptitle(suptitle)
fig.tight_layout()
learning_rate = 0.1
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
model, loss_history = train(X, y, model, loss_fn, optimizer, 5000)
show_result(X, y, model, loss_history)
Done!
Layer: 0.weight | Size: torch.Size([1, 2]) | Values : tensor([[ 1.2848, -2.9980]], grad_fn=<SliceBackward0>)
Layer: 0.bias | Size: torch.Size([1]) | Values : tensor([0.0889], grad_fn=<SliceBackward0>)
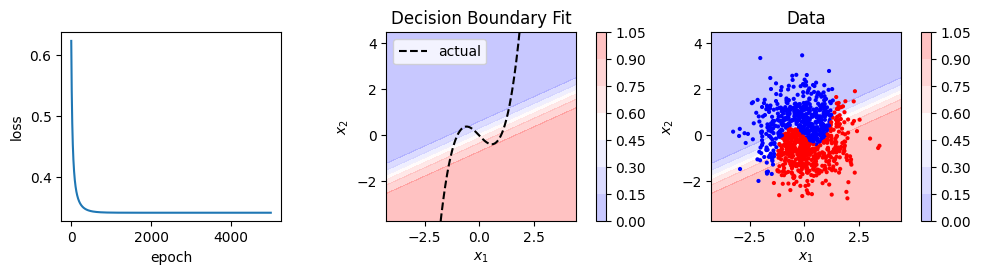
Logistic regression, and our neural network that recreates it, can only fit linear decision boundaries. We could fit a non-linear boundary by adding polynomial features. In this case we’d need up cubic terms so we might try to fit something like this:
Note that \(z\) is linear in the weights so this is still logistic regression.
Could neural networks provide an alternative to creating all these features manually?
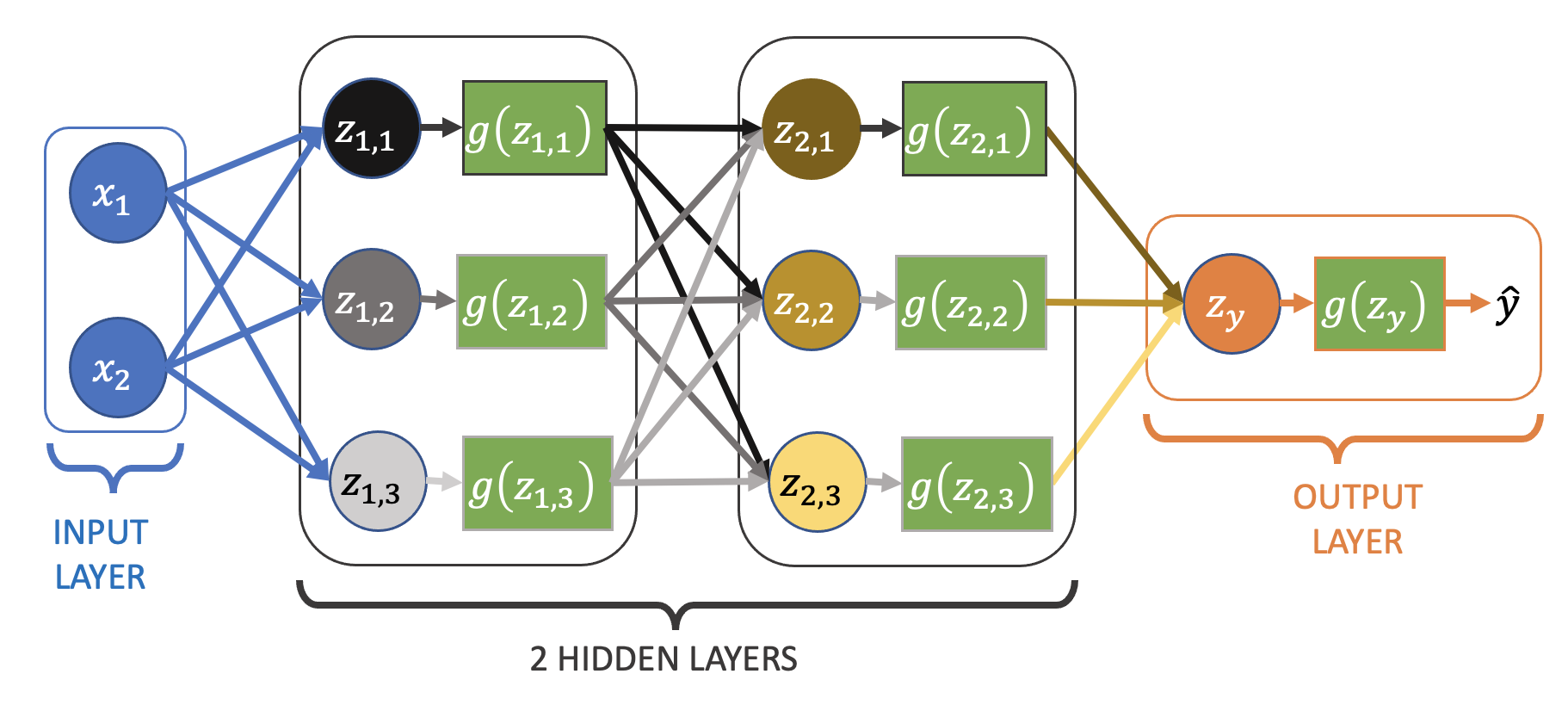
Adding nodes and layers (moving away from logistic regression)#
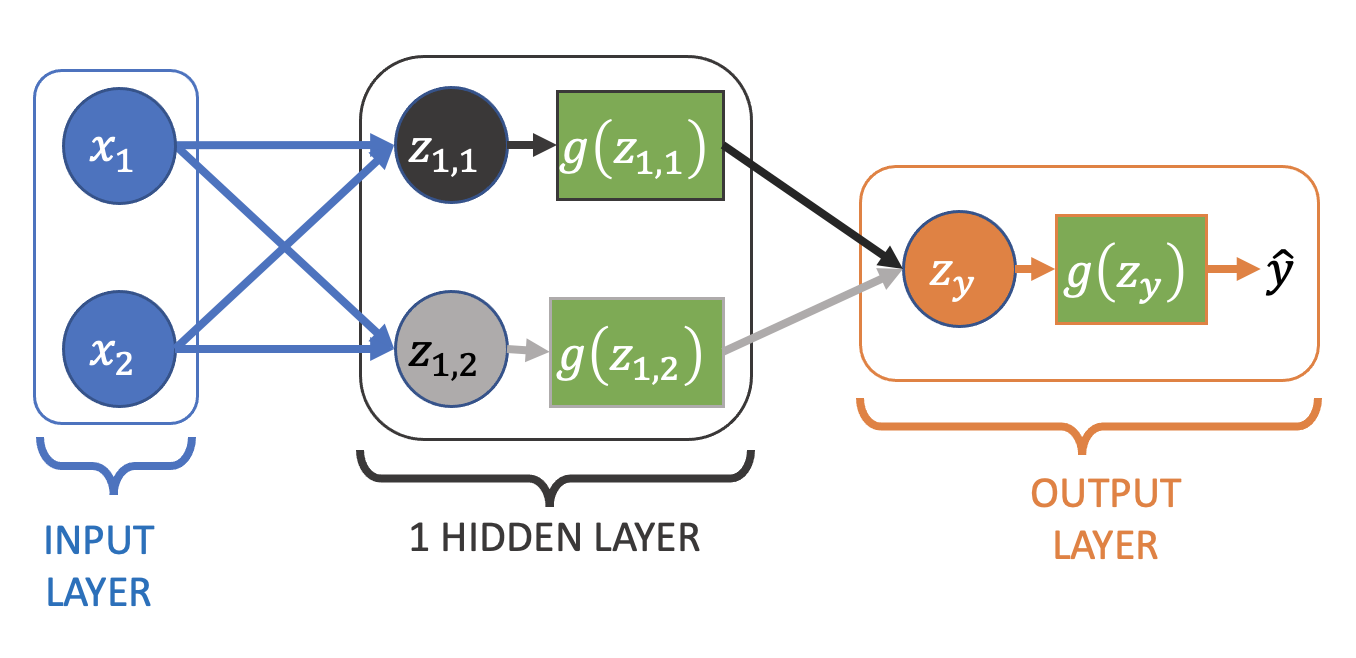
For our linear regression network with no/linear/identity activation we saw adding nodes and layers had no effect on the type of function that could be fitted. How about adding nodes/layers to our logistic regression network, which has sigmoid activation?
What’s going on?#
Let’s go back to the one hidden layer network:
model = nn.Sequential(
nn.Linear(in_features=2, out_features=2),
nn.Sigmoid(),
nn.Linear(in_features=2, out_features=1),
# Sigmoid (applied in loss_fn)
)
learning_rate = 0.2
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
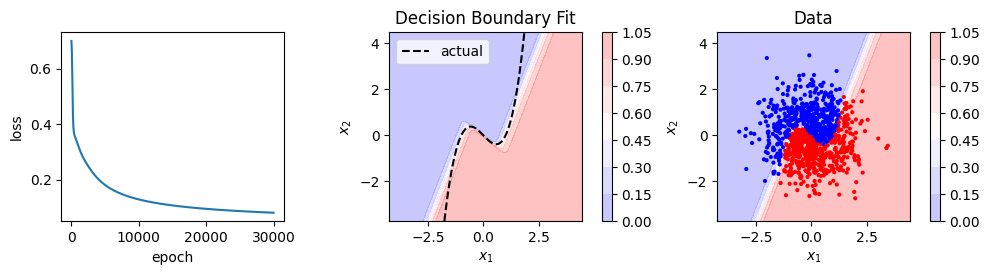
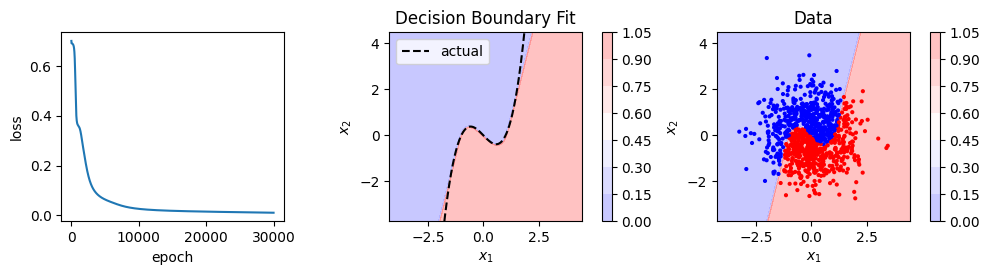
model, loss_history = train(X, y, model, loss_fn, optimizer, 30000)
Done!
We can visualise the input and output of each node to get an idea of how the non-linear decision boundary is created:
fig, ax = plt.subplots(2, 2, figsize=(8, 7))
# 1st hidden node
w00 = model[0].weight[0]
b00 = model[0].bias[0]
fn00 = lambda x: (w00 * x + b00).sum(axis=1)
g00 = sigmoid(fn00(X).detach())
plot_decision_boundary(
X,
y,
fn00,
show_data=False,
show_actual=True,
ax=ax[0][0],
title="Hidden Node 1",
)
# 2nd hidden node
w01 = model[0].weight[1]
b01 = model[0].bias[1]
fn01 = lambda x: (w01 * x + b01).sum(axis=1)
g01 = sigmoid(fn01(X).detach())
plot_decision_boundary(
X,
y,
fn01,
show_data=False,
show_actual=True,
ax=ax[0][1],
title="Hidden Node 2",
)
# Output node
a1 = np.array([g00.numpy(), g01.numpy()]).T # output of hidden layer
fn10 = (
lambda a1: model[2].weight[0][0] * a1[:, 0]
+ model[2].weight[0][1] * a1[:, 1]
+ model[2].bias
)
# Output vs. hiddden node activations
plot_decision_boundary(
a1,
y,
fn10,
show_data=True,
ax=ax[1][0],
show_actual=False,
xlim=(-0.01, 1.01),
ylim=(-0.01, 1.01),
title="Output Layer\n(activation of hidden nodes)",
xlabel="Hidden Node 1 Activation",
ylabel="Hidden Node 2 Activation",
)
# Output vs. input data values
plot_decision_boundary(
X,
y,
model,
show_data=True,
show_actual=False,
ax=ax[1][1],
title="Output Layer\n(input features)",
)
fig.tight_layout()
/tmp/ipykernel_1914/854895806.py:2: RuntimeWarning: overflow encountered in exp
return 1 / (1 + np.exp(-z))
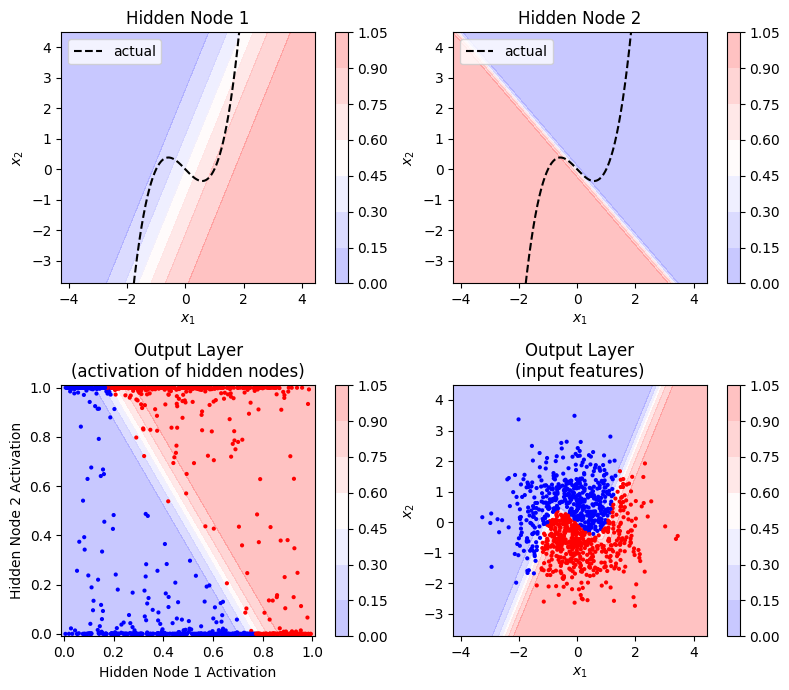
The colour scale shows the “activation” of the node (i.e. the output after applying the sigmoid function). One node in the hidden layer captures the upward (positive) slope of the decision boundary, and the other the downward (negative) slope. When combined in the output layer (and sigmoid applied), the points from the two classes are linearly separable (you can draw a linear decision boundary between them) with respect to the activation of the hidden nodes.
Takeaway message#
Adding non-linear activation functions (e.g. sigmoid) to the output of every node allows us to fit non-linear functions with neural networks.
References#
“Deriving Machine Learning Cost Functions using Maximum Likelihood Estimation (MLE) - Part II”, Allen Akinkunle
“Supervised Machine Learning: Regression and Classification” (Coursera), Andrew Ng