05: Gradients and Activation Functions#
Possible structure:
Vanishing gradients
Sigmoid
through backprop
ReLu
(leaky ReLu) - maybe
Exploding gradients
weight initialisation
gradient clipping
(Normalisation?) - maybe
(Tanh)
(Batch norm)
What activation function to use
output layer
hidden layers
Activation Functions: Recap#
Remember that the activation function, \(g(z)\), is applied to the linear combination of a node’s inputs, \(z\):
And so far we have seen two different activation functions:
Linear activation: \(g(\mathbf{Z}^{[l]}) = \mathbf{Z}^{[l]}\)
Output layer: Used for regression problems
Hidden layers: Usually not used (as then only linear functions can be fitted)
Sigmoid activation: \(g(\mathbf{Z}^{[l]}) = \mathrm{sigmoid}\left(\mathbf{Z}^{[l]}\right) = \sigma\left(\mathbf{Z}^{[l]}\right)\)
Output layer: Used for (binary) classification problems
Hidden layers: Can be used to fit non-linear functions, but generally not used (we’ll see why later)
To compute the \(\color{blue}{\partial \mathbf{A}^{[l]} / \partial \mathbf{Z}^{[l]}}\) terms we need to know the derivative of the activation function.
Repeating Terms in Back Propagation#
As an example, let’s consider a four-layer network:

Each layer is represented by only one node in the diagram (but can actually contain many nodes without changing the equation below).
Here is the loss-gradient for the weights in the first layer of the four-layer network, in matrix notation:
where two groups of similar terms are highlighted:
\(\color{blue}{\partial \mathbf{A}^{[l]} / \partial \mathbf{Z}^{[l]}}\): The gradient of the node activations in a layer (with respect to the node’s inputs).
\(\color{red}{\mathbf{W}^{[l]^T}}\): The weights in a layer.
and the other terms are:
\(\partial \mathcal{L} / \partial \mathbf{A}^{[4]} = \partial \mathcal{L} / \partial \mathbf{\hat{y}}\): The gradient of the loss with respect to our predictions (aka the activations of the last, in this case the fourth, layer)
\(\mathbf{A}^{[0]^T} = \mathbf{X}^T\): The input data (aka the activations of the zeroth layer).
\(1/m\): To take the mean gradient across the data batch (which has \(m\) samples)
In this notebook, we’re going to focus on how, in certain situations, the form of this equation can make it difficult to learn (optimise) the weights of the network, and in particular the weights in the early layers of a deep network.
The Gradient of the Sigmoid Function#
We’re going to start by considering the activation gradient terms (\(\color{blue}{\partial \mathbf{A}^{[l]} / \partial \mathbf{Z}^{[l]}}\)) above.
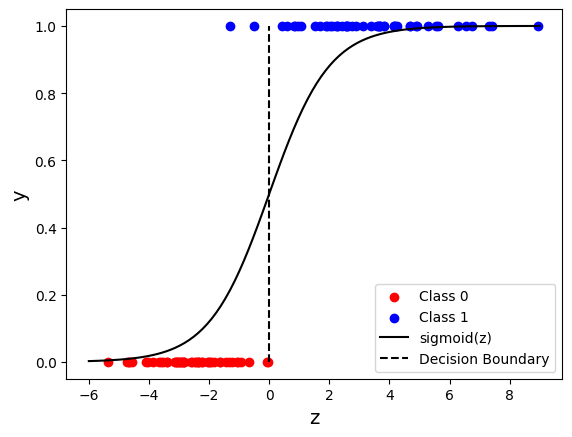
The sigmoid function, \(\sigma(z)\), is defined as:
and its derivative is:
They look like this:
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(z):
return 1 / (1 + np.exp(-z))
def dsigmoid_dz(z):
return sigmoid(z) * (1 - sigmoid(z))
z = np.linspace(-7, 7, 100)
fig, ax = plt.subplots(2, 1, sharex=True, sharey=True, figsize=(4, 8))
ax[0].plot(z, sigmoid(z), color="b", label=r"$\sigma(z)$")
ax[0].legend()
ax[0].set_xlabel("z")
ax[0].set_title("Sigmoid")
ax[1].plot(z, dsigmoid_dz(z), color="orange", label=r"$\sigma'(z)$")
ax[1].legend()
ax[1].set_xlabel("z")
ax[1].set_title("Gradient")
ax[0].set_ylim([-1.1, 1.1])
ax[1].set_ylim([-1.1, 1.1])
(-1.1, 1.1)
def dtanh_dz(z):
return 1 - np.tanh(z)**2
z = np.linspace(-7, 7, 100)
fig, ax = plt.subplots(2, 1, sharex=True, sharey=True, figsize=(4, 8))
ax[0].plot(z, np.tanh(z), color="b", label="tanh(z)")
ax[0].legend()
ax[0].set_xlabel("z")
ax[0].set_title("tanh")
ax[1].plot(z, dtanh_dz(z), color="orange", label=r"tanh'(z)")
ax[1].legend()
ax[1].set_xlabel("z")
ax[1].set_title("Gradient")
ax[0].set_ylim([-1.1, 1.1])
ax[1].set_ylim([-1.1, 1.1])
(-1.1, 1.1)
def step(z):
return z >= 0
def dstep_dz(z):
return 0 * z
z = np.linspace(-7, 7, 101)
fig, ax = plt.subplots(2, 1, sharex=True, sharey=True, figsize=(4, 8))
ax[0].plot(z, step(z), color="b", label="step(z)")
ax[0].legend()
ax[0].set_xlabel("z")
ax[0].set_title("step")
ax[1].plot(z, dstep_dz(z), color="orange", label="step'(z)")
ax[1].plot([0, 0], [0, 10], color="orange")
ax[1].legend()
ax[1].set_xlabel("z")
ax[1].set_title("Gradient")
ax[0].set_ylim([-1.1, 1.1])
ax[1].set_ylim([-1.1, 1.1])
(-1.1, 1.1)
Note that:
The maximum gradient of the sigmoid function is 0.25 (\(0 \leq \mathrm{d}\sigma / \mathrm{d}z \leq 0.25\))
The gradient is close to zero for most values of \(z\) (especially for \(z < -5\) and \(z > 5\))
Vanishing Gradients#
To help gain intuition about why the form of the sigmoid’s gradient can be problematic, let’s consider the case where:
our four-layer example network really does only have one node per layer
all the weights are one (\(\mathbf{W}^{[1]} = \mathbf{W}^{[2]} = \mathbf{W}^{[3]} = \mathbf{W}^{[4]} = 1\))
all the biases are zero (\(\mathbf{b}^{[1]} = \mathbf{b}^{[2]} = \mathbf{b}^{[3]} = \mathbf{b}^{[4]} = 0\))
there’s only one input (\(x\)).
In this case the network computes:
And the loss gradient for the weights in each layer (for one data sample \(x\)) are:
Where the inequalities follow from \(\mathbf{A}^{[l]} = \sigma(\mathbf{Z}^{[l]}) \leq 1\) and \(\color{blue}{\partial \mathbf{A}^{[l]} / \partial \mathbf{Z}^{[l]}} = \partial \sigma(\mathbf{Z}^{[l]}) / \partial \mathbf{Z}^{[l]} \leq 0.25\).
Or visually, here are the activations and gradients in each layer plotted, assuming log loss is used and the true class is \(y = 0\):
def activations_gradients(x, y, layers, g, dg_dz, dL_dyhat):
# forward pass
A = {0: x}
Z = {}
for l in range(1, layers + 1):
Z[l] = A[l - 1]
A[l] = g(Z[l])
# always sigmoid output layer
Z[layers] = A[layers - 1]
A[layers] = sigmoid(Z[layers])
# backward pass
# always sigmoid output layer
dL_dZ = {layers: dL_dyhat(y, A[layers]) * dsigmoid_dz(Z[layers])}
dL_dW = {layers: dL_dZ[layers] * A[layers - 1]}
for l in range(layers - 1, 0, -1):
dL_dZ[l] = dL_dZ[l + 1] * dg_dz(Z[l])
dL_dW[l] = dL_dZ[l] * A[l - 1]
return A, dL_dW
def dL_dyhat(y, yhat):
"""Log loss derivative"""
return - y / yhat + (1 - y) / (1 - yhat)
def plot_activations_gradients(x, y, A, dL_dW):
fig, ax = plt.subplots(1, 2, sharex=True, sharey=False, figsize=(12, 5))
for l in range(1, layers + 1):
ax[0].plot(x, A[l], label=f"Layer {l}")
ax[1].plot(x, dL_dW[l], label=f"Layer {l}")
ax[0].legend()
ax[0].set_xlabel("x")
ax[0].set_title("Layer Activations")
ax[1].legend()
ax[1].set_xlabel("x")
ax[1].set_title(
r"Layer Loss-Gradients ($\partial \mathcal{L} / \partial W^{[l]}$) if "
f"y = {y}"
)
layers = 4
x = np.linspace(-7, 7, 100)
y = 1
A, dL_dW = activations_gradients(x, y, layers, sigmoid, dsigmoid_dz, dL_dyhat)
plot_activations_gradients(x, y, A, dL_dW)
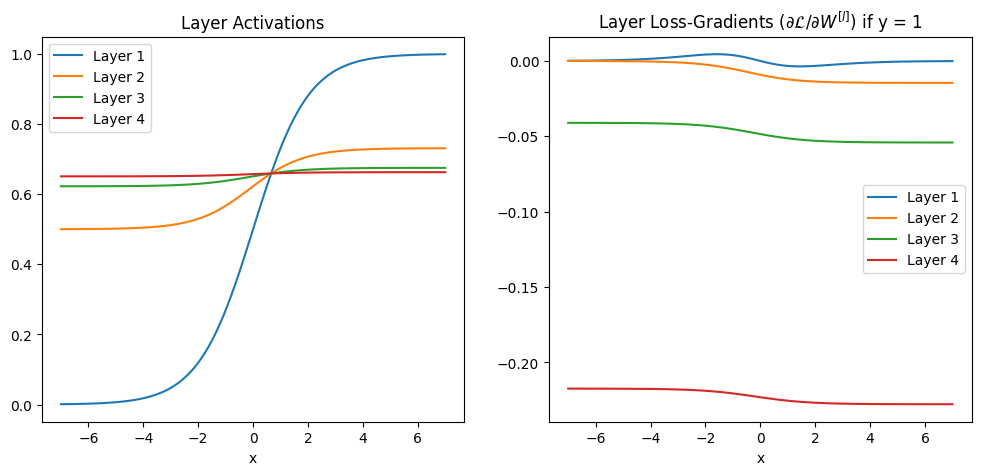
In both the equations and the plot we can see the gradients are getting closer and closer to zero as we move to earlier layers in the network - they are vanishing.
Why are Vanishing Gradients a Problem?#
We want to train bigger, deeper networks to learn more complex functions
We update the weights of the network with gradient descent, computing the derivative of the loss with respect to the weights
If the gradients are close to zero in a layer we won’t change the weights in those layers
With sigmoid activation the gradients get closer and closer to zero as we move back through the layers
We stop learning (don’t update the weights) in earlier layers!
ReLU#
def relu(z):
r = z.copy()
r[r < 0] = 0
return r
def drelu_dz(z):
dr = z.copy()
dr[z < 0] = 0
dr[z >= 0] = 1
return dr
z = np.linspace(-5, 5, 200)
fig, ax = plt.subplots(1, 2, sharex=True, sharey=True, figsize=(9, 4))
ax[0].plot(z, relu(z), color="b", label="ReLU(z)")
ax[0].legend()
ax[0].set_xlabel("z")
ax[1].plot(z, drelu_dz(z), color="orange", label="ReLU'(z)")
ax[1].legend()
ax[1].set_xlabel("z")
ax[0].set_title("ReLU")
ax[1].set_title("Gradient")
Text(0.5, 1.0, 'Gradient')
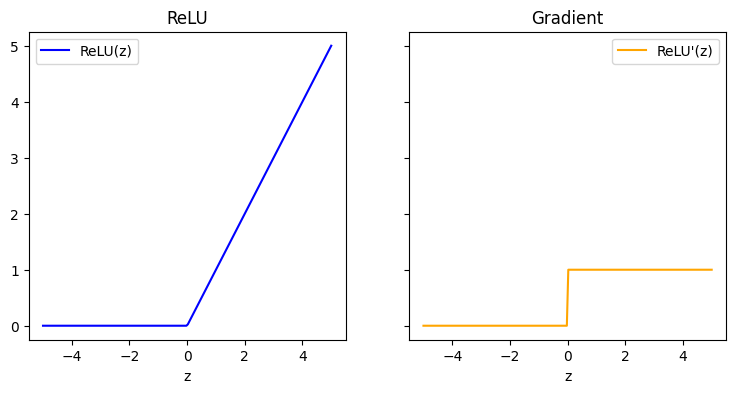
4-Layer Network Example with ReLU#
but still sigmoid on output
layers = 4
x = np.linspace(-7, 7, 100)
y = 1
A, dL_dW = activations_gradients(x, y, layers, relu, drelu_dz, dL_dyhat)
plot_activations_gradients(x, y, A, dL_dW)
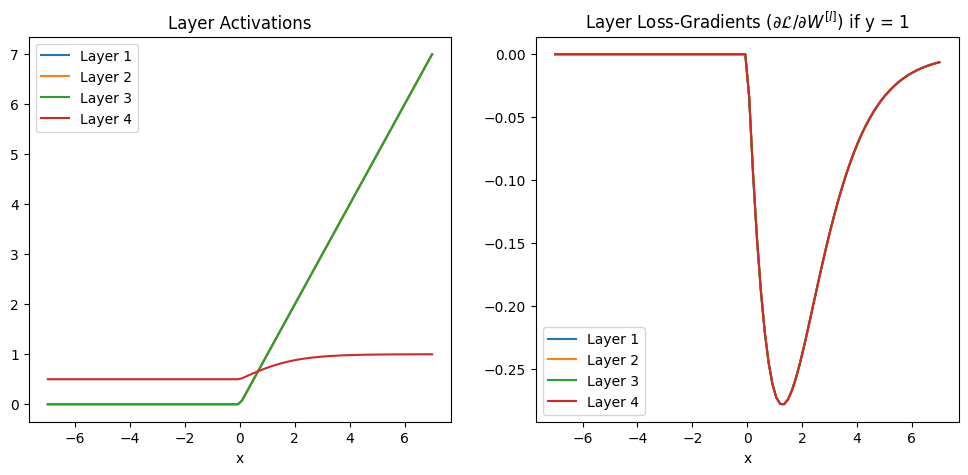
Exploding Gradients#
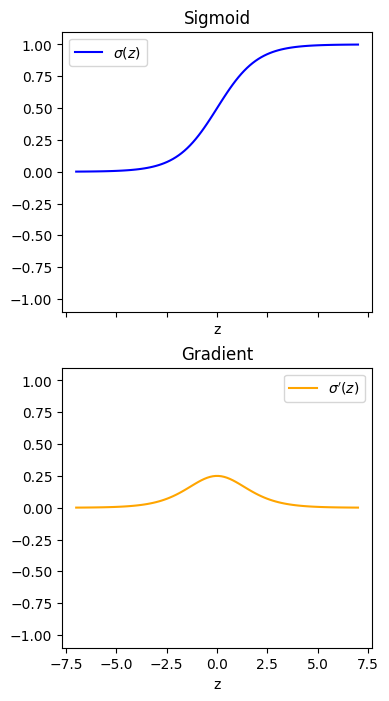
Other Activation Functions#
tanh, normalisation
leaky relu
others
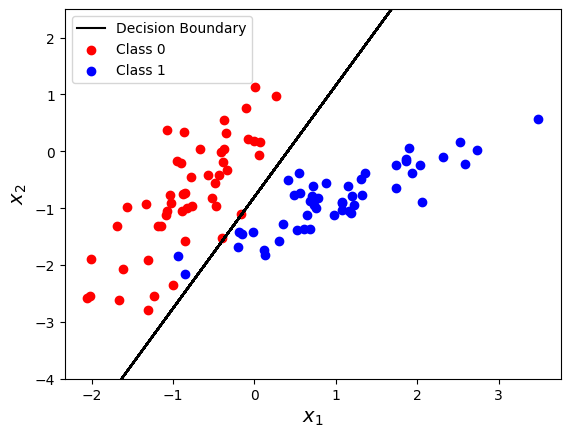
import sklearn.datasets
X, y = sklearn.datasets.make_classification(
n_samples=100, n_features=2, n_informative=2, n_redundant=0, n_classes=2,
n_clusters_per_class=1, random_state=5, class_sep=0.9
)
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
clf.fit(X, y)
yhat = clf.predict(X)
# Retrieve the model parameters.
b = clf.intercept_[0]
w1, w2 = clf.coef_.T
# Calculate the intercept and gradient of the decision boundary.
c = -b/w2
m = -w1/w2
plt.plot(X[:, 0], m * X[:, 0] + c, "k", label="Decision Boundary")
plt.scatter(X[y == 0, 0], X[y == 0, 1], c="r", label="Class 0")
plt.scatter(X[y == 1, 0], X[y == 1, 1], c="b", label="Class 1")
plt.legend()
plt.ylim([-4, 2.5])
plt.xlabel(r"$x_1$", fontsize=14)
plt.ylabel(r"$x_2$", fontsize=14)
Text(0, 0.5, '$x_2$')
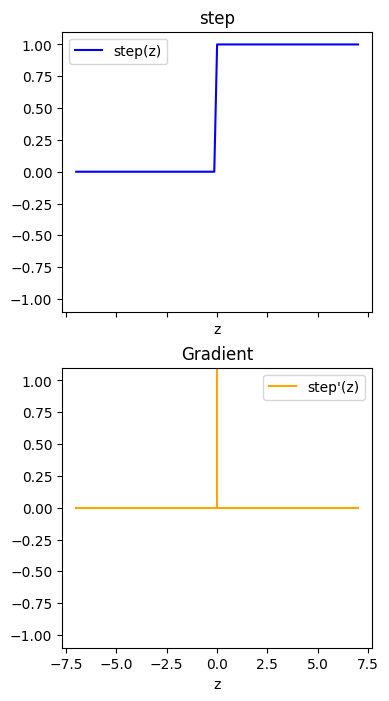
z = w1 * X[:, 0] + w2 * X[:, 1] + b
plt.scatter(z[y == 0], y[y == 0], c="r", label="Class 0")
plt.scatter(z[y == 1], y[y == 1], c="b", label="Class 1")
z = np.linspace(-6, 9, 100)
sigz = 1 / (1 + np.exp(-z))
plt.plot(z, sigz, "k", label="sigmoid(z)")
plt.plot([0, 0], [0, 1], "k--", label="Decision Boundary")
plt.xlabel("z", fontsize=14)
plt.ylabel("y", fontsize=14)
plt.legend()
<matplotlib.legend.Legend at 0x7faa69b47520>